6. Stable Operations and Optimization
Overview
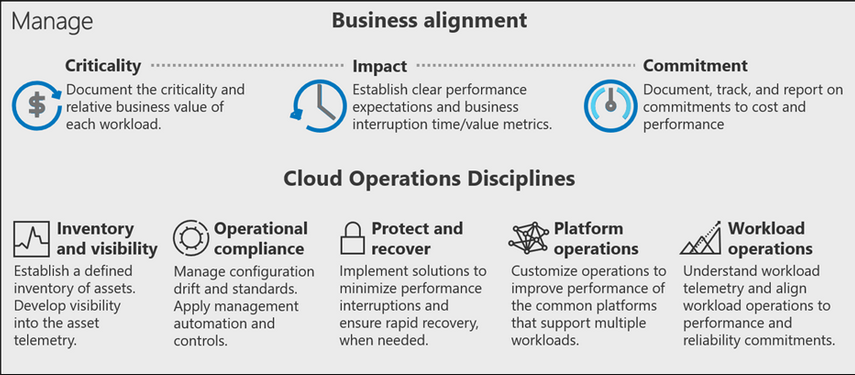
A management baseline is the minimum set of tools applied to all resources in the environment. This module walks through the three disciplines in a cloud-management baseline:
- Inventory and visibility: Inventorying assets and creating visibility into the run state of each resource of a workload
- Operational compliance: Management of configuration, sizing, cost, and performance of assets
- Protection and recovery: Data protection and quick recovery to minimize operational interruptions
Each cloud workload should have:
- A management baseline for the cloud environment. The fundamental management baseline is for all workloads,
- extra features for specific platforms and workloads.
- reporting on management costs for the business stakeholders.
Clearly Defined: (see above)
- criticality
- impact
- commitment
Establish Business Commitments
Criticality
Firm wide acceptance and acknowledgement of a tier. DR Tier may suffice here. Set all to a middle ground and then raise or lower the priority Revisit the priority with regular audits.
- Mission-critical: The workload affects the company's mission and might noticeably affect corporate profit-and-loss statements.
- Unit-critical: The workload affects the mission of a specific business unit and its profit-and-loss statements.
- High: The workload might not affect the company's mission, but affects high-importance processes.
- Medium: Impact on processes is likely. Losses are low or immeasurable, but brand damage or upstream losses are possible.
- Low: Impact on business processes isn't measurable. No brand damage or upstream losses are likely. Localized impact on a single team is expected.
- Unsupported: No business owner, team, or process associated with this workload can justify any investment in the workload's ongoing management.
Impact
How much this application costs per hour of downtime. A critical application will cost the firm much much more than a development application Another metric would be user impact - how many users will be impacted
Commitment
Document the partnership between the business and IT. Have signoffs from all involved for each workload
Management baseline is a promise to deliver a set of services. Based on the services, calculate a SLA Document the groups responsible for this workload
Operations Baseline
Consistency is key
-
Resource consistency: If all resources are organized the same way and tagged the same way, other management tasks become more manageable.
-
Environment consistency: If all landing zones are organized the same way, then management and troubleshooting become much more manageable.
-
Resource configuration consistency: As with resources and landing zones, it's crucial to monitor resource configuration. If a configuration setting is changed, it can trigger an automation job to restore the environment. Configuration drift control works here, but only if it restores, not impacts the workload
-
Resource optimization: Regular monitoring of resource performance reveals trends in resource utilization and opportunities to optimize the cost and performance of each resource.
-
Update consistency: All updates to the environment should be done in a scheduled, controlled, and possibly automated way. Controlled change management reduces unnecessary outages and troubleshooting.
-
Remediation automation: Automation for quick remediation of common incidents is a great way to increase customer satisfaction and minimize outages. However, you should fix known issues by their root causes. Fixing a root cause is often a long process, and automation is a quick fix.
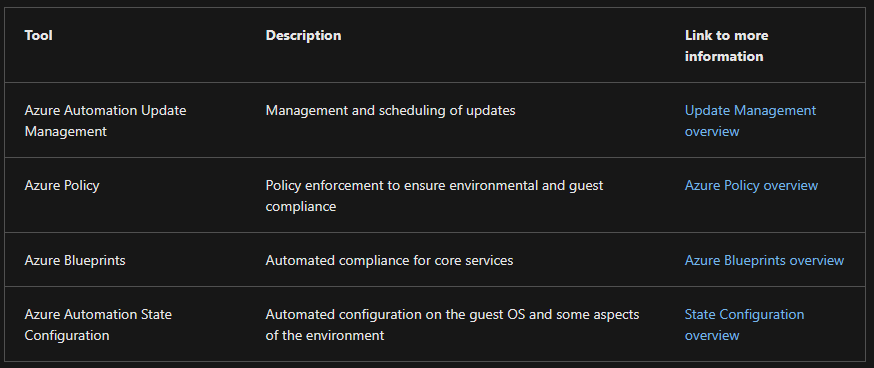
Azure Blueprints is being deprecated - Use Terraform for this.
https://learn.microsoft.com/en-us/azure/developer/terraform/
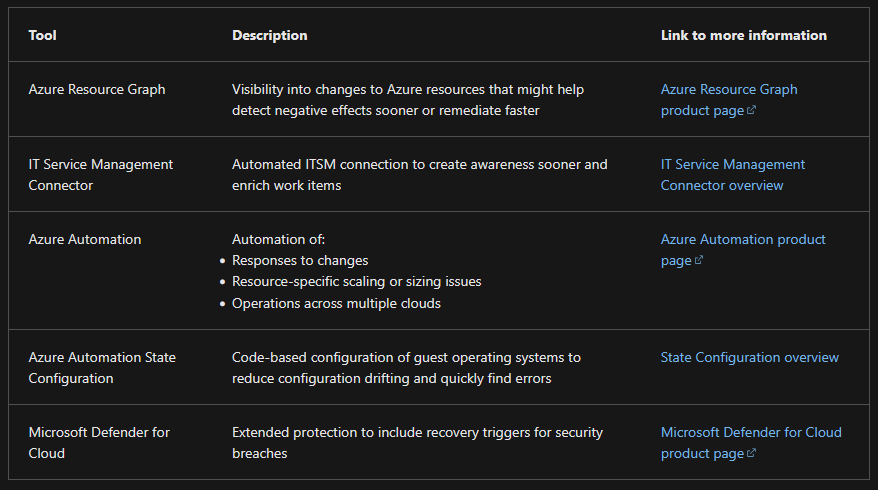
Protect and Recover
- Azure Backup
- Azure Site Recovery
- MS Defender for Cloud
- Or other third party solutions like Veeam or Crowdstrike or Symantec or Commvault.
Enhance an operations baseline
If all of your workloads need a better baseline than the default, set a new baseline as the default.
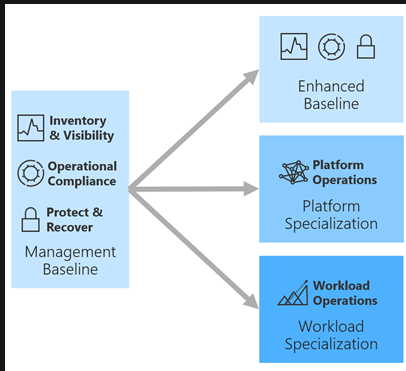 Workload specialization is for the most mission-critical workloads, which make up about 20 percent of the workloads.
Platform specialization is for the platform or platforms that run the most high-criticality workloads. The specialized platform investment is often divided over many workloads.
Workload specialization is for the most mission-critical workloads, which make up about 20 percent of the workloads.
Platform specialization is for the platform or platforms that run the most high-criticality workloads. The specialized platform investment is often divided over many workloads.
Workload Specialization
Workload-specific management usually requires in-depth knowledge about the specific workload, which is why the workload team or development team often does it. A workload-specific solution doesn't scale quickly to other workloads. Centralized IT can still guide and share knowledge with the workload-specialized team on operations.
Platform specialization
Decentralized, workload-specific operations aren't scalable across an enterprise, but a study of the portfolio often identifies common platforms on which those workloads run. Those technology platforms (also known as technology stacks) are often at the heart of workload-specific incidents. When priority workloads share a common technology platform, it might be more valuable for central IT to focus on improving those platforms' operations, and thereby reduce or avoid workload-specific operations.
- Examples of technology platforms might include data platforms, analytics platforms, container platforms, Azure Virtual Desktop platforms, enterprise resource planning (ERP) platforms, or even mainframes.
Advanced operations
Platform and workload specialization consists of disciplined execution of the following four processes in an iterative approach:
- Improve system design: Technical debt and architectural flaws are the root cause of most business workload outages. By reviewing the platform or workload design, you can improve stability. The Azure Well-Architected Framework includes recommendations for improving the quality of the platform or a specific workload.
- Automate remediation: Some design improvements aren't cost-effective, because the technical debt can be too costly or complex to improve. In such cases, it might make more sense to automate remediation and reduce the effect of interruptions.
- Scale the solution: As system design and automated remediation are improved, those changes can be scaled across the environment through the service catalog. You can publish optimized platforms and solutions in Azure Managed Applications Center to easily reuse them for other workloads or external customers.
- Continuously improve: You'll gain valuable information for the next system review by collecting feedback from users, administrators, and customers. Collecting and visualizing critical system logs and performance data are also important. Both the feedback and the data collected will be used as a foundation for making new decisions about future system improvements.